
Learning Flow Fields in Attention是什么
Learning Flow Fields in Attention(Leffa)是一种新的技术,它通过在注意力机制中学习流场来实现可控人物图像生成。这种方法主要专注于解决以前遇到的问题,即参考图像中的细粒度纹理细节常常被扭曲。Leffa通过引入基于扩散的正则化损失,明确引导目标查询在注意力层中找到正确的参考键,以此提高注意力的精准度。它在虚拟试穿和姿势变换方面实现了极佳的效果,减少了细粒度细节的失真,同时保持了高图像质量。
Learning Flow Fields in Attention截图展示
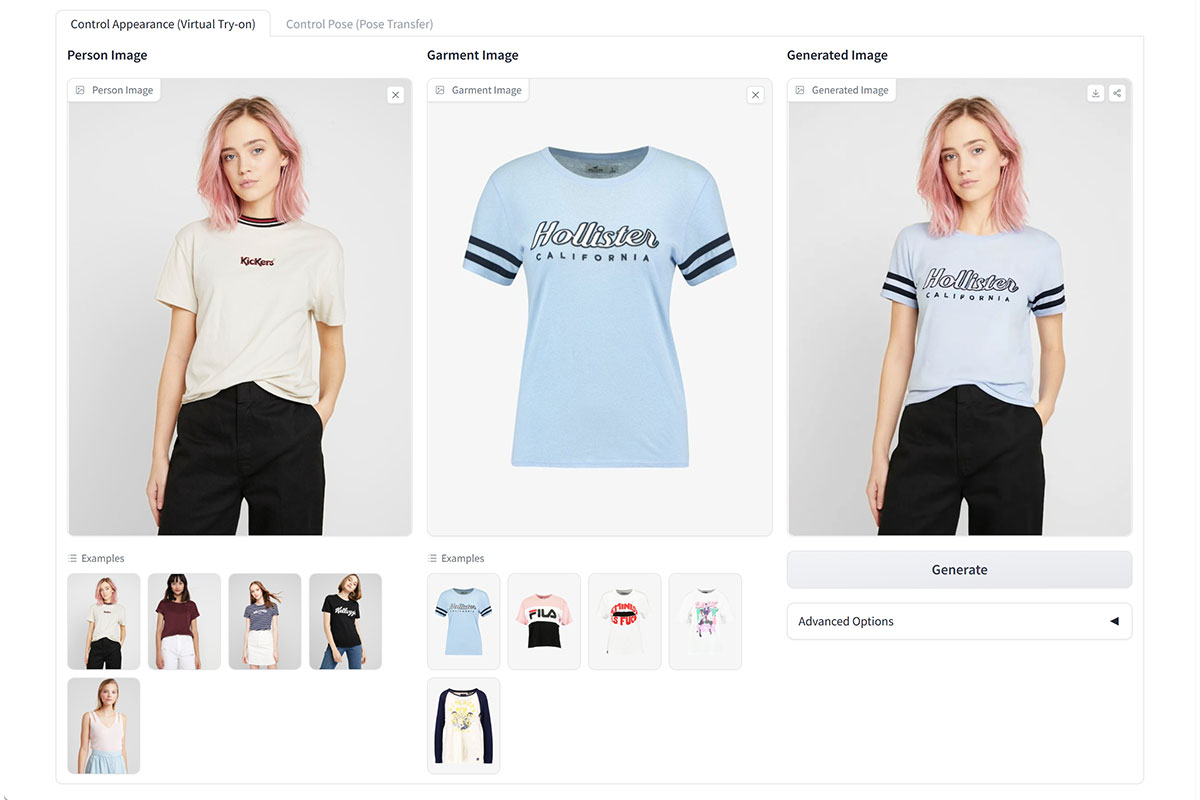
Learning Flow Fields in Attention主要功能
- 减少细粒度失真:通过改进的注意力机制,减少生成图像中的纹理和细节失真。
- 控制人物外观和姿势:允许用户精确控制生成的人物图像的外观和姿势。
- 高图像质量:即使在改进细节处理的同时,仍维持生成图像的高质量。
- 模型泛化能力:Leffa中引入的损失函数与模型无关,可以被应用于其他扩散模型中,提高其性能。
Learning Flow Fields in Attention官网
声明:本站资源均整理自互联网,版权归原作者所有,仅供学习交流使用,请勿直接商用,若需商用请购买正版授权。因违规使用产生的版权及法律责任由使用者自负。部分资源可能包含水印或引流信息,请自行甄别。若链接失效可联系站长尝试补链。若侵犯您的权益,请邮件(将 # 替换为 @)至 feedback#tgoos.com,我们将及时处理删除。转载请保留原文链接,感谢支持原创。